
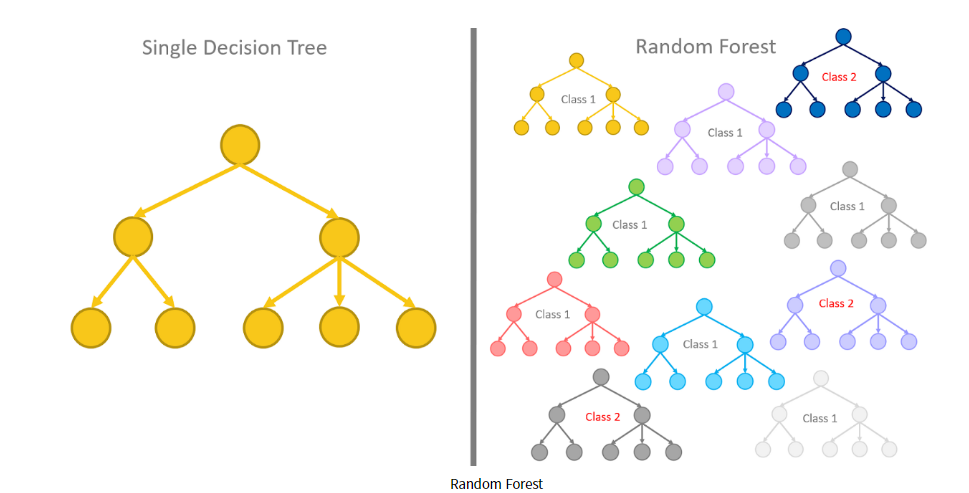
* Random Forest
- Decision Tree의 확장판
- Tree를 여러개를 사용하면 더 성능이 좋아짐
- 다수의 의사결정나무(Decision Tree)를 사용하여 서로 다른 모델을 조합하여 새로운 모델을 만듬
- 앙상블(Ensemble) : 여러가지 모델을 사용하여 정확도를 개선
- 다양성(diverse)과 임의성(random)을 부여
- Overfitting(과적합) 발생 가능성을 줄 일 수 있다.
- 예측은 증가하고, 잘못된 예측은 상쇄 역할

* bagging(bootstrap + aggregating)
- 기존 데이터를 사용하여 여러개의 train data를 생성
- 서로 다른 train data를 decision tree를 만듬
- Bootstrap 데이터는 기존 데이터에서 단순 복원 임의 추출함.(중복된 데이터가 들어갈 수 있음)


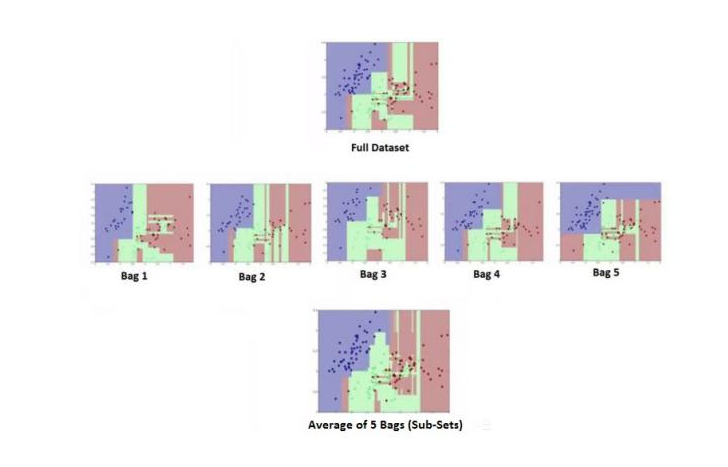
* 2가지를 적용가능
- 분류모델(다수결로 선택) : 예측값 = {1,1,0,1,1,0,0,1,1,1} =1
- 예측모델(평균값으로 선택) : 예측값 = {55, 50, 45, 50, 50} = 50
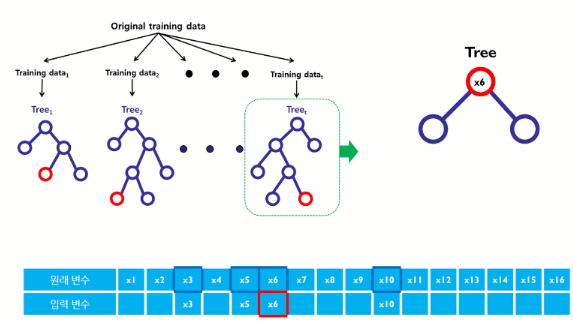
* 임의성(Random) : x의 변수 몇개를 랜덤하게 지정하여 그 중 entropy가 제일 낮은 변수 를 선택
* SMOTE :KNN 기법을 사용하여 샘플을 주면 값과 비슷하게 맞추어서 성능을 더 좋게 만드는 기법
* LightGBM : 부스팅 기법으로 tree를 순차적으로 생성하여 안좋은 값들을 개선하여 다시 tree를 만들어 성능을 좋게 만드는 기법
'인공지능(AI)' 카테고리의 다른 글
| Supervised - Softmax Regression (0) | 2020.10.21 |
|---|---|
| epochs, batch size, iteration (0) | 2020.10.20 |
| Supervised - Descision Tree (0) | 2020.10.19 |
| Supervised - Logistic Regression and Validation (0) | 2020.10.19 |
| Supervised - Logistic Regression - Cross Entropy Error (CEE) (0) | 2020.10.19 |