
RL(reinforce learning)강화학습
액션 : agent가 각 state 에서 취할 수 있는 action(동작) 의 옵션들
특정 state에 있을 때, 특정 actiondㅡㄹ 취하면 얻을 수 있는 reward가 있음
정책 : 특정 상태에서 어떤 행동을 취할 지 정해 놓은 것
value function 을 찾아내는 것이 목표
optimal policy :
목표를 달성하기 위해 모든 state에서 취해야할 적절한 action(행동)이 계산되어 있는 상태 => 강화학습 목표
예) cart-pole balancing, 게임 대부분 강화학습에 적용, 자율주행,지능형 로봇, 주식 거래(대규모지분 매각 시점 찾는데 탁웡ㄹ 투자자 손실을 최소화 및 최적의 이익을 취할 수 있는 가격대)
GAN(Generative Adversarial Network)
2016 GAN 관심 폭발
최근 10년간 머신러닝 분야에서 혁신적인 아이디어
G : 무엇인가를 생성하는 - 생성모델은 그럴듯한 가짜를 만드는 모델, 진짜같은 가짜사람얼굴, 실제로 있음직한 풍경들
A : 대립하는 ,대립을 위해서는 2개 이상 모델이 필요
N : 뉴럴 네트워크 모델
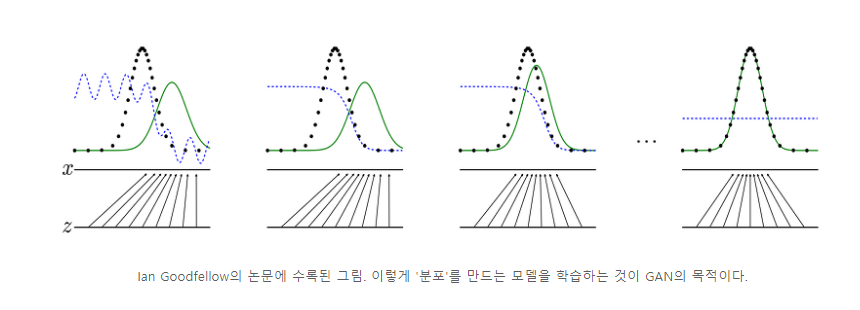
개요: 기존데이터 분포를 알아내어 이 분포에 해당 하는 값을 생성하면됨 -데이터의 양이 많아야함.
예) 180cm/82kg , 167cm/65kg과 같은 사람 키/몸무게 데이터 생성 가능, 190cm/23kg과 같이 불가능한 데이터는 생성하지 않음
경쟁 속에서 두 그룹 모두 서로의 능력이 발전되고 결과적으로 진짜와 가짜를 구별할 수 없을 정도가 됨
위조범이 0.5와 감별자가 0.5가되는 지점.
Discriminator : 보고있는 데이터가 원본 데이터일 확률을 계산
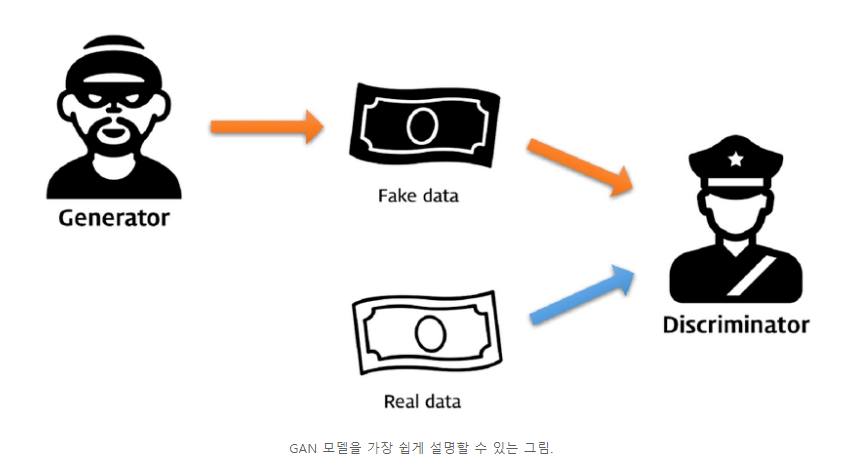
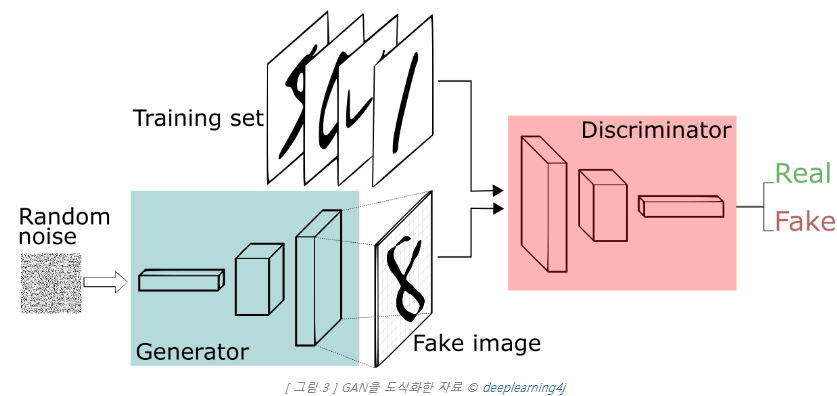
mode collapse : 학습을 하지 못하는 현상 , 2개 모델이 성능이 차이가 있을떄
'인공지능(AI)' 카테고리의 다른 글
| keras (0) | 2020.11.05 |
|---|---|
| output layer - softmax() (0) | 2020.11.04 |
| RNN(Recurrent Neural network), LSTM (0) | 2020.11.03 |
| Deep Learning (딥러닝) (0) | 2020.11.03 |
| classifier model- 앙상블 (0) | 2020.11.03 |