
과대적합
모델이 학습될 수록 훈련 데이터에 fit된 모델이 만들어짐
->훈련 데이터 이외 새로운 데이터(테스트 데이터에는 일반화 성능이 떨어짐
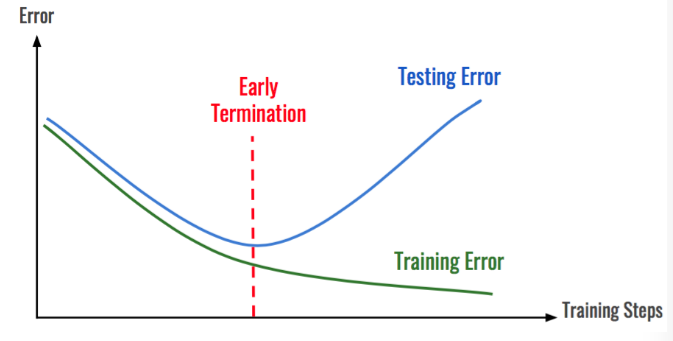
early termination 이후에는 testing error와 training error차이가 크며
testing error는 training step이증가할 수록 testing error가 증가한다. 즉, 학습할 수록 새로운 데이터의 에러율이 증가한다는것 즉, 오버피팅이발생하는것으로 볼 수 있다.
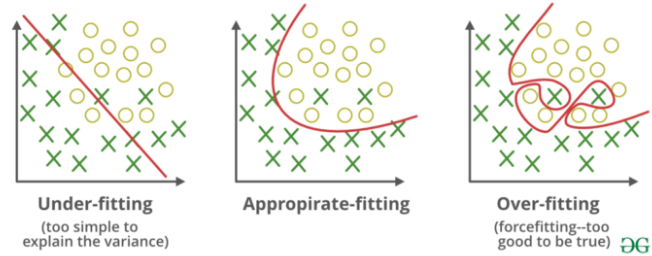
최적화 : 가능한 훈련 데이터 에서 최고 성능을 얻으려고 모델 조정 과정
일반화 : 훈련된 모델이 이전에 보 적없는 데이터에서 얼마나 잘 수행 되는지를 봄
딥러닝은 일반화가 더 중요하다.
과대적합 피한느 과정
더 많은 훈련데이터를 가짐
네트워크 축소
규제(regularization)
네트워크 축소
-모델 크기 를 줄이는 방법
모델 의 용량이 너무 크면 훈련 데이터 쉽게 학습하지만 일반화 능력 없음
용량이 너무 작으면 훈련 샘플과 타깃 사이의 매핑을 쉽게 학습 하지 못함
너무 많은 용량과 충분하지 않은 용량 사이 절충점을 찾아야함
알맞은 층의 수나 각 층의 유닛 수를 결정 할 수 있는 공식 없음
데이터에 알맞은 모델크기를 찾으려면 각기다른 구조를 평가해 보여야함
w,b가 많으면 좀더 완벽하게 fitting 되지만 overfit이 빨리됨-> 그래서 퍼셉트론 사이즈를 줄이는게 필요함.(어느정도 일반화가 필요하다는 얘기)
1) epochs 수를 변경
'인공지능(AI)' 카테고리의 다른 글
| CNN (0) | 2020.11.06 |
|---|---|
| 신경망에서 과대적합을 방지하기 위한 방법 (0) | 2020.11.06 |
| 성능지표 (0) | 2020.11.05 |
| keras (0) | 2020.11.05 |
| output layer - softmax() (0) | 2020.11.04 |